
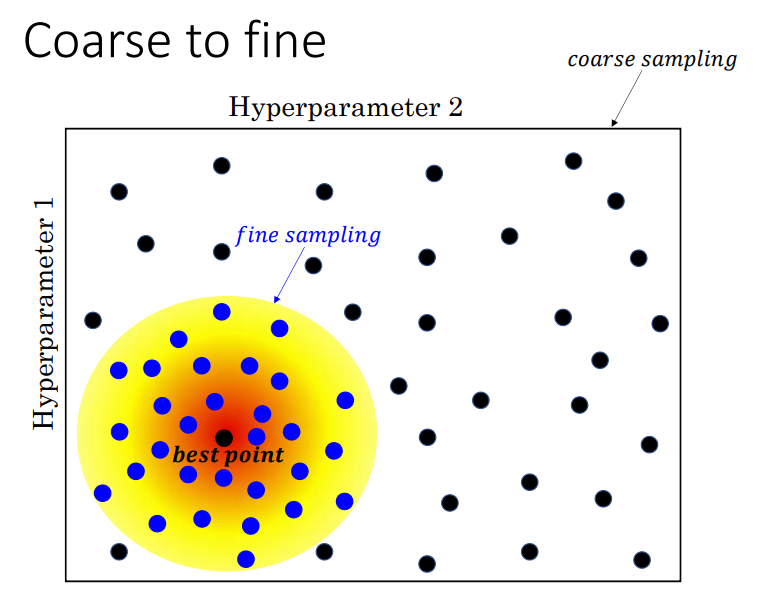
an empirical process where we iteratively experiment, evaluate, and refine hyperparameters based on observed performance!!

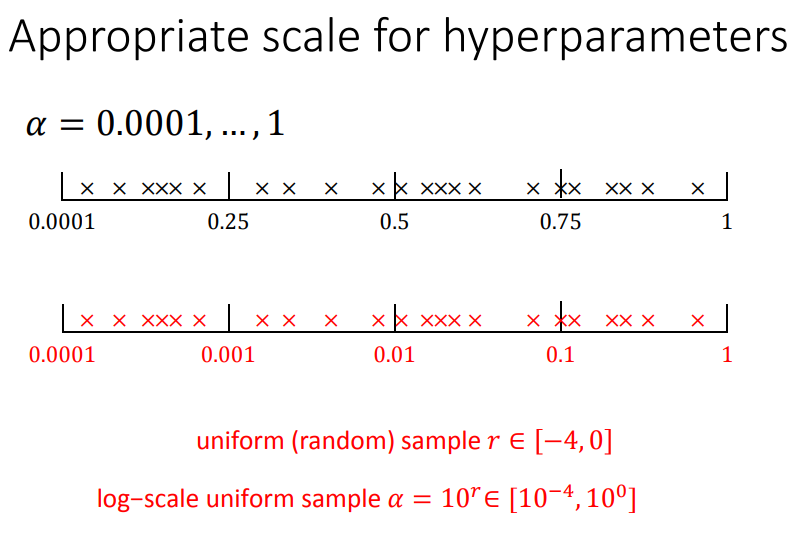
왜 그런거냐면? parameter 들이 성능에 영향을 미치는 정도가 각각 다른데..randomly sampling 하면 경우의 수가 많아지면서 중요한 parameter 를 많이 찾게 되는것이다. (근데 물론 uniform distrubution 로 sampling 를 해야 한다)




Batch Normalization
- One of the most important algorithms in deep learning created by Sergey Ioffe and Christian Szegedy
- Makes the hyperparameters search problem much easier
- Make the neural network much more robust to the choice of hyperparameters
- There is a much bigger range of hyperparameters that work well
- Enable you to much more easily train even very deep networks

일단 우리는 앞에 input 만 normalize 했는데.. 그럼 layer 별로 normalization 를 하면 어떨까? => 차원의 영향을 균등하게 해준다. 그걸 batch normalization 라고 말하고 보통 z 에 한다 . 왜냐? activation layer 를 통과하면서 a 는 이미 범위가 동일하게 되어있고 값 차이가 많이 나는 z 는 해주는게 현식적이다.

Batch Norm 적절한 스케일과 평균으로 바꿀 수 있게 해주는 것인데 그거로 부족해! γ β 두개도 넣어서 같이 학습시켜주겠다. 그리고 자세히 보면 이 두개는 미분도 되고 mean, variance 근처에 와다리 가다리 학습중인 것들이다.



Why does batch norm work?
- Normalizing the input features to mean zero and variance one speed up learning
- Batch norm is doing a similar thing, but for the values in the hidden units and not just for the input units
- But, this is just a partial picture for what batch norm is doing and there are a couple of futher intuitions
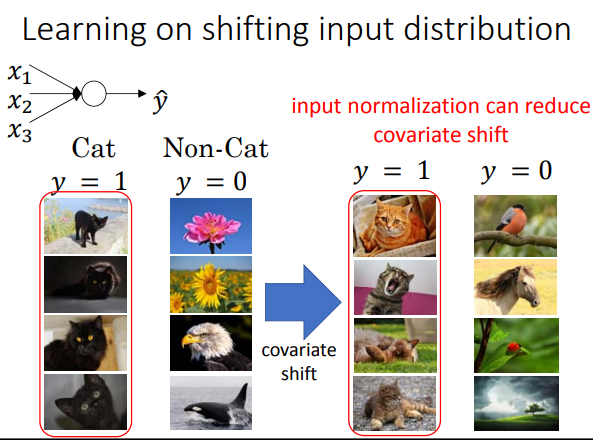
그럼 왜 그런 문제가 생기냐? 검정에만 집중해서 그렇다. 근데 batch norm 방법은 normalization 해주면서 색깔에 관계없이 각 색깔 vector component 들의 상관관계 분포를 바꿔준다.
Why this is a problem with neural networks

Batch Norm as regularization
- Each mini‐batch is scaled by the mean/variance computed on just that mini‐batch.
- This adds some noise to the values within that minibatch. So similar to dropout, it adds some noise to eash hidden layer's activations
- This has a slight regularization effect.

mini-batch마다 평균과 분산이 조금씩 다름으로 같은 샘플이라도 batch가 달라지면 정규화 결과가 조금 달라짐. noise injection 효과가 생겨서 regularization 역할을 한다.
여기서 쓰는 μ, 는 현재 test batch에서 계산한 값이 아니라, 훈련 과정에서 모아 둔 추정값을 사용한다
'학교수업 > 딥러닝' 카테고리의 다른 글
| 딥러닝 족보문제 (0) | 2026.04.11 |
|---|---|
| Multi‐class Classification (0) | 2026.04.08 |
| Optimization Algorithms (0) | 2026.03.23 |
| Setup and Regularization for training (0) | 2026.03.17 |
| Deep Neural Network (0) | 2026.03.16 |